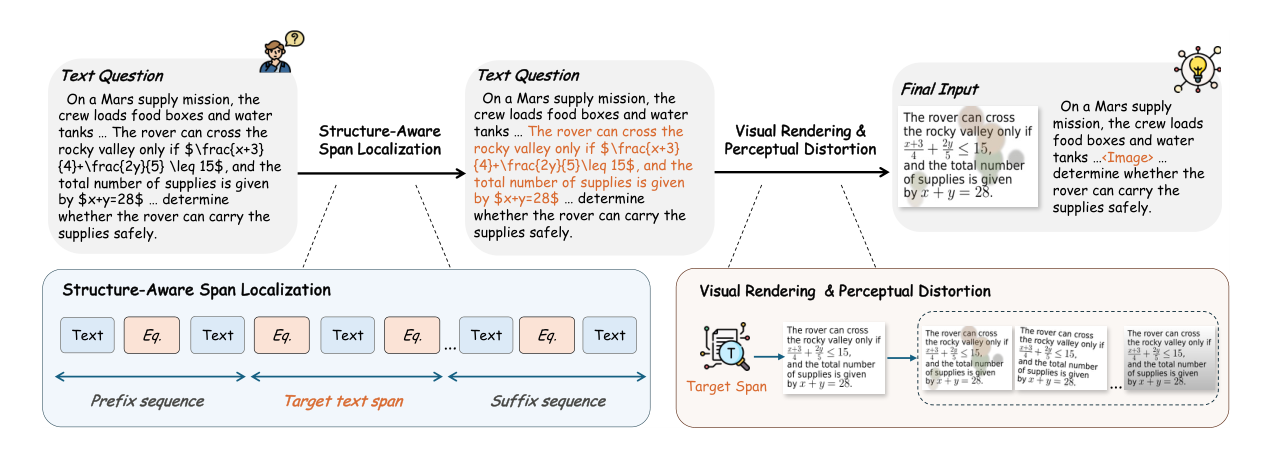
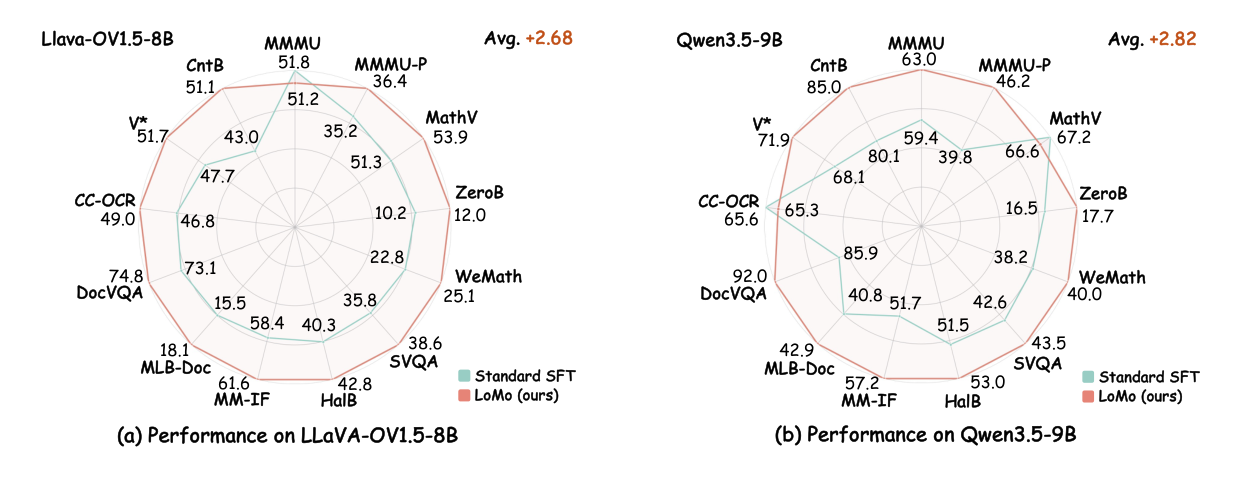
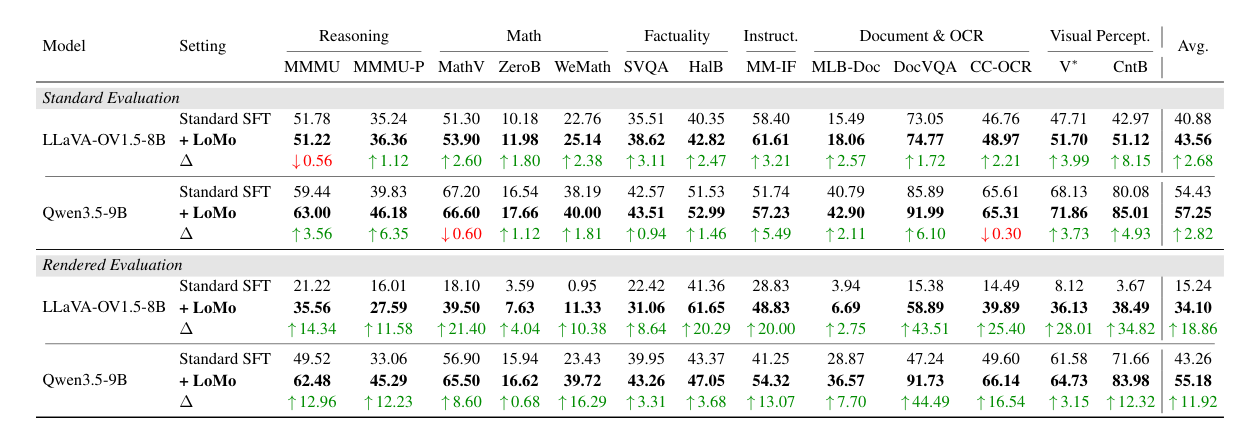
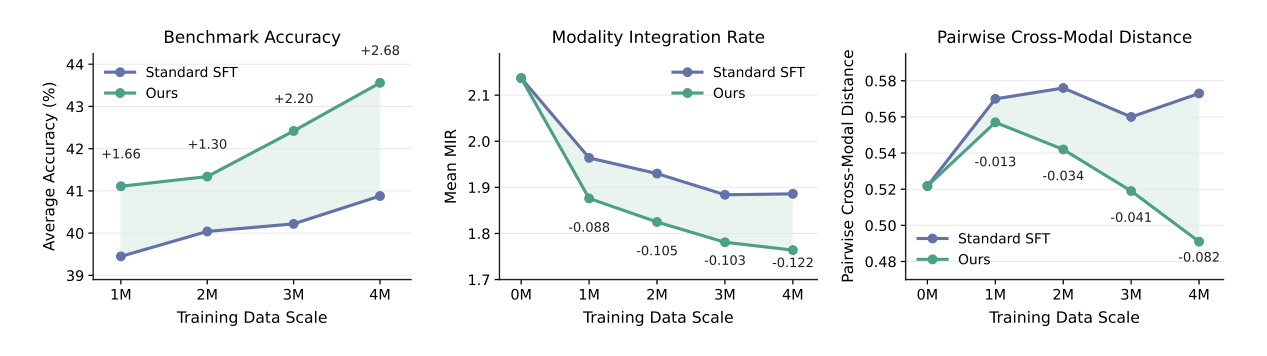
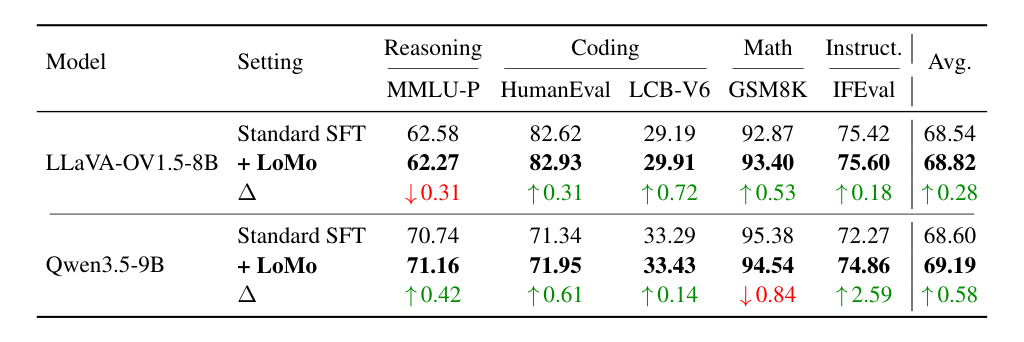
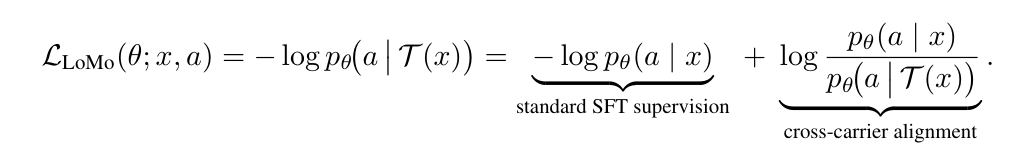Carrier Sensitivity in VLMs
Replacing a textual question with its rendered-image counterpart should ideally leave VLM performance essentially unchanged because the semantics are the same. In practice, this local modality substitution causes large accuracy drops, and larger cross-modal representation distances lead to stronger degradation.
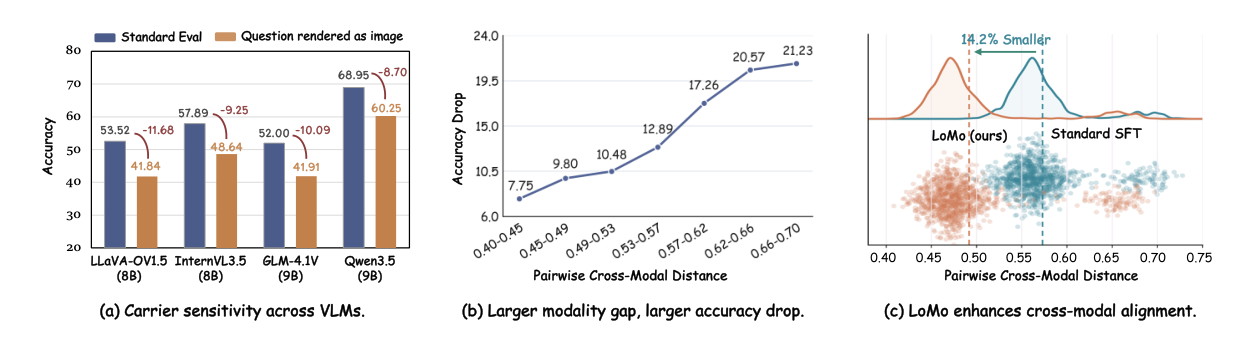
(a) Rendering the same question as an image causes a clear accuracy drop across strong VLMs. (b) Samples with larger text-image representation distance suffer larger performance degradation. (c) LoMo shifts paired representations closer together, indicating stronger cross-carrier alignment.